
Our team (including Dr. Aaron Dinner at UChicago and Dr. Julia Damerow at Arizona State) is fine-tuning unsupervised figure extraction software called PicAxe. Give PicAxe a corpus of PDFs, then it removes text and extracts the remaining figures. It’s not perfect, but it’s much faster than extracting images by hand, one-by-one.
For more details on how PicAxe works, read our paper published (2025) in the Journal of Open Research Software!
If you're interested in using PicAxe or getting involved, check out our GitHub and contact me!
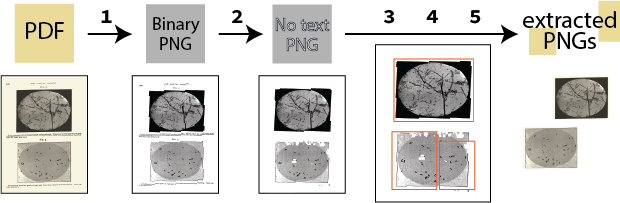
Scientific images are almost always published alongside text in articles, books, and on the internet.
In order to analyze published scientific images with computers, you first need to extract them from their original text-image environments and create relevant metadata.
Extracting images manually from large corpora of digital documents is tedious and time consuming. Many researchers who want to study large groups of images don’t have the time or technical skills to automate this process, so we are doing it for them!